According to a recent case study by the University of Texas and Chitika, the top 50,000 blogs on the Internet generated $500 million in ad revenue last year. That sounds all well and good but I think the methodology to come up with the $500 million number is questionable.
Chitika took their 12,000 publishers, found their Technorati ranking and how much they made from Chitika in 2006. Then they made the assumption that the blogs will run three revenue sources and came up with a revenue number.
Using Chitika revenue numbers from 2006 and assuming that bloggers will, on average, diversify across. 3 revenue sources, and assuming that they will typically try out other sources that will generate similar revenue streams, it is safe to estimate that the total estimated revenue for their blog will be at least 3 times the revenue attained through Chitika. With the sample data set, (BlogID, Rank, 2006 Revenue) standard statistical predictive modeling techniques (in this case, the specific regression model used was a variant of the Pareto model) were used to estimate the advertising revenue earned by blogs across all ranks.
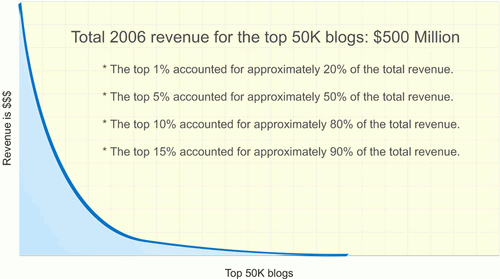
When the all the numbers were crunched, the case study came up with this summary of findings.

Ad revenue in a blog is more sensitive to the rank of the blog than what one would expect in a typical Zipf Law 80/20 curve situation. One reason for this may be the social value of advertising in a blog. If online advertising is like advertising in a mall, advertising in the blogosphere is like advertising in a country club.
I never advertised in a country club before. How does that work?